3.7. Autocorrelation and autocovariance#
Look at the speech signal segment below. On a large scale it is hard to discern a structure, but on a small scale, the signal seems continuous. Speech signals typically have such structure that samples near in time to each other are similar in amplitude. Such structure is often called short-term temporal structure.
More specifically, samples of the signal are correlated with the preceding and following samples. Such structures are in statistics measured by covariance and correlation, defined for zero-mean variables x and y as
where \(E[ \cdot ]\) is the expectation operator.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
import scipy
# read from storage
filename = 'sounds/test.wav'
fs, data = wavfile.read(filename)
window_length_ms = 20
window_length = int(np.round(fs*window_length_ms/1000))
n = np.linspace(0.5,window_length-0.5,num=window_length)
#windowpos = np.random.randint(int((len(data)-window_length)))
windowpos = 92274
datawin = data[windowpos:(windowpos+window_length)]
datawin = datawin/np.max(np.abs(datawin)) # normalize
plt.plot(n*1000/fs,datawin)
plt.xlabel('Time (ms)')
plt.ylabel('Amplitude')
plt.title('A window of a signal')
plt.tight_layout()
plt.show()
For a speech signal \(x_{n}\), where \(n\) is the time-index, we would like to measure the correlation between two time-indices \(x_{n}\) and \(x_{h}\). Since the structure which we are interested in appears when \(n\) and \(h\) are near each other, it is better to measure the correlation between \(x_{n}\) and \(x_{n-k}\). The scalar \(k\) is known as the lag. Furthermore, we can assume that the correlation is uniform over all \(n\) within the segment. The self-correlation and -covariances, known as the autocorrelation and autocovariance are defined as
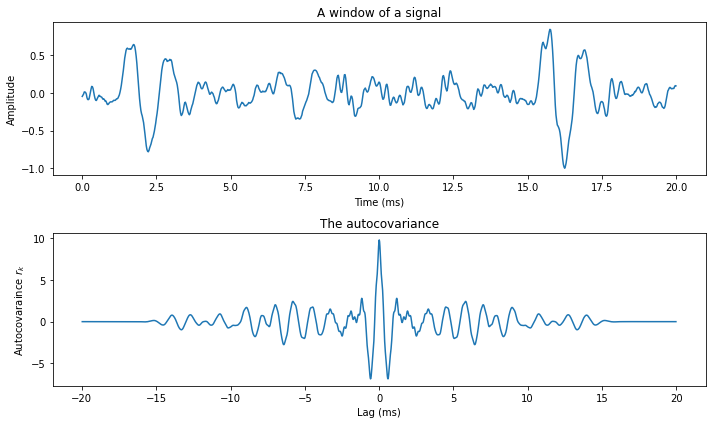
The figure below illustrates the autocovariance of the above speech signal. We can immediately see that the short-time correlations are preserved - on a small scale, the autocovariance looks similar to the original speech signal. The oscillating structure is also accurately preserved.
Because we assume that the signal is stationary, and as a consequence of the above formulations, we can readily see that autocovarinaces and -correlations are symmetric
This symmetry is clearly visible in the figure below, where the curve is mirrored around lag 0.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
import scipy
import scipy.fft
# read from storage
filename = 'sounds/test.wav'
fs, data = wavfile.read(filename)
window_length_ms = 20
window_length = int(np.round(fs*window_length_ms/1000))
n = np.linspace(0.5,window_length-0.5,num=window_length)
n2 = np.linspace(1-window_length,window_length-1,num=window_length*2)
# windowing function
windowing_fn = np.sin(np.pi*n/window_length)**2 # sine-window
#windowpos = np.random.randint(int((len(data)-window_length)))
windowpos = 92274
datawin = data[windowpos:(windowpos+window_length)]
datawin = datawin/np.max(np.abs(datawin)) # normalize
spectrum = scipy.fft.rfft(datawin*windowing_fn,n=2*window_length)
autocovariance = scipy.fft.irfft(np.abs(spectrum**2))
autocovariance = np.concatenate((autocovariance[window_length:],autocovariance[0:window_length]))
plt.figure(figsize=[10,6])
plt.subplot(211)
plt.plot(n*1000/fs,datawin)
plt.xlabel('Time (ms)')
plt.ylabel('Amplitude')
plt.title('A window of a signal')
plt.subplot(212)
plt.plot(n2*1000/fs,autocovariance)
plt.xlabel('Lag (ms)')
plt.ylabel('Autocovaraince $r_k$')
plt.title('The autocovariance')
plt.tight_layout()
plt.show()
The above formulas use the expectation operator \(E[\cdot ]\) to define the autocovariance and -correlation. It is an abstract tool, which needs to be replaced by a proper estimator for practical implementations. Specifically, to estimate the autocovariance from a segment of length \(N\), we use
Observe that the speech signal \(x_{n}\) has to be windowed before using the above formula.
We can also make an on-line estimate (a.k.a. leaky integrator) of the autocovariance for sample position \(n\) with lag \(k\) as
where \(\alpha\in[0,1]\) is a small positive constant which determines how rapidly the estimate converges.
It is often easier to work with vector notation instead of scalars, whereby we need the corresponding definitions for autocovariances. Suppose
We can then define the autocovariance matrix as
Clearly \(R_{x}\) is thus a symmetric Toeplitz matrix. Moreover, since it is a product of \(x\) with itself, \(R_{x}\) is also positive (semi-)definite.