13. Computational models of human language processing#
One area of research making use of speech technology is the study of human language learning and processing. Language is a highly complex phenomenon with physical, biological, psychological, social and cultural dimensions. Therefore it is also studied across several disciplines, such as linguistics, neuroscience, psychology, and anthropology. While many of these fields primarily focus on empirical and theoretical work on language, computational models and simulations provide another important aspect to the research: capability to test theoretical models in practice. Implementation of models capable of processing real speech data requires techniques from speech processing and machine learning. For instance, techniques for speech signal representation and pre-processing are needed to interface the models with acoustic speech recordings. Different types of classifiers and machine learning algorithms are needed to implement learning mechanisms in the models or to analyze behavior of the developed models. In addition, model training data may be generated with speech synthesizers (e.g., [Havard et al., 2017]), whereas linguistic reference data for model evaluation may be extracted from speech recordings using automatic speech recognition.
The basic idea of computational modeling is to understand how humans learn and process language by implementing human-like learning and speech processing capabilities as computational algorithms. The models are then exposed to inputs similar to what humans observe, and the model behavior is then recorded and compared to human data (Fig. 1). Computational models can focus on questions such as how adult speech perception operates (e.g., the highly-influential TRACE model of speech perception; McClelland and Elman [1986]), how language learning takes place in young children (native language aka. L1 learners; e.g., [Dupoux, 2018, Räsänen, 2012]) or in second-language (L2) learners, or they may study the emergence and evolution of language through communicative coordination between multiple agents (see, e.g., Kirby [2002], Steels [1997], for overviews).
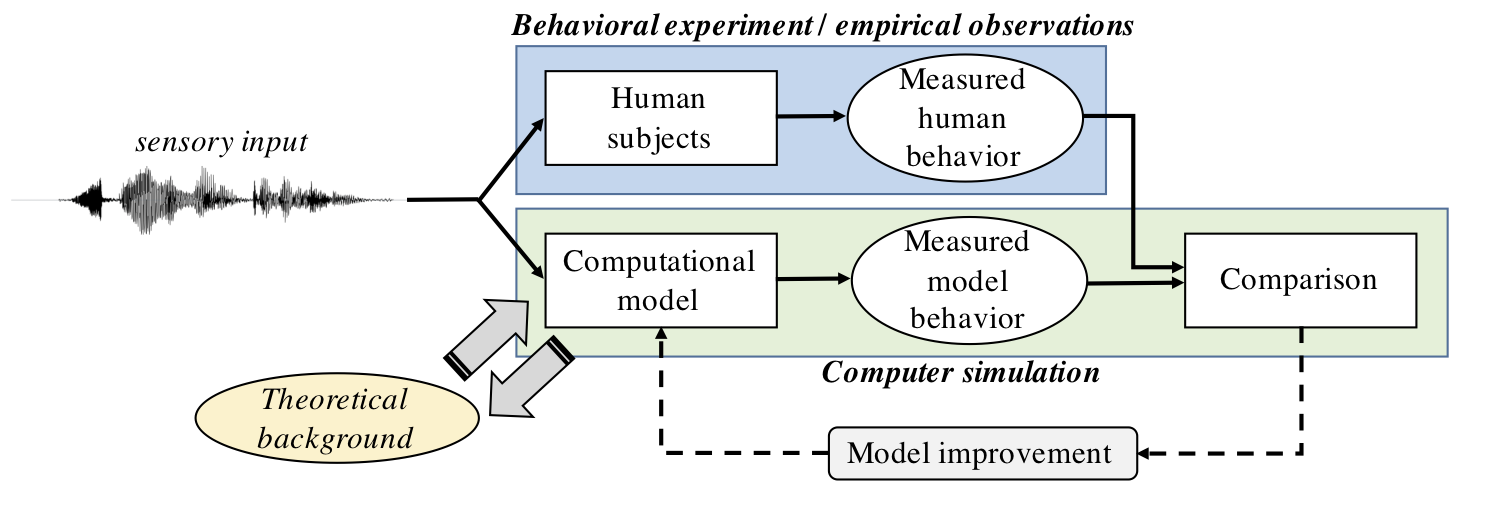 Figure 1: A high-level schematic view of a typical computational model development and evaluation process.
Figure 1: A high-level schematic view of a typical computational model development and evaluation process.
13.1. Human cognition as a sensorimotor information processing system#
Computational modeling research is based on the metaphor of human brain as a computational information processing system. From an external observer viewpoint, this system perceives the environment using a number of input channels (senses), processes the information using some type of processing steps (the nervous system), and creates outputs (motor actions) based on the available sensory information and other internal states of the system. This input/output-relationship is affected by developmental factors and learning from earlier sensorimotor experience, realized as changes in the connectivity and structure of the central nervous system. Computational research attempts to understand the components of this perception-action loop by replacing the human physiology and neurophysiology with computational algorithms for sensory (or sensorimotor) information processing. Typically the aim is not to replicate information processing of the brain at the level of individual neurons, but to focus on the computational and algorithmic principles of the process, i.e., the information representation, flow and transformation within the system (see Marr’s levels of analysis; Marr [1982]). These processing steps could then be implemented in infinitely many ways using different hardware (biological neurons, silicon chips architectures, CPU instruction sets, quantum computing etc.) or translations from computational description to implementation-specific instructions (consider, e.g., different programming languages with the same CPU instruction set). Despite the implementation differences, the observed behavior of the system in terms of inputs and the resulting outputs can still be similar.
To give an example, a model of adult spoken word recognition could focus on explaining the acoustic, phonetic and/or other linguistic factors that affect the process of word recognition. Such a model could focus on the details of how word recognition process evolves over time when a spoken word is heard, describing how alternative word candidates are being considered or rejected during this process (see, e.g., Magnuson et al. [2020], Weber and Scharenborg [2012], for examples). Even if the model would not focus on modeling neurons of the human brain, it could still explain how our minds decode linguistic information from speech input. This explanation could include how the process is affected by factors such as noisy environments, misprounciations, distributional characteristics of the input, or non-native language background of the listener—all useful information to understand both theoretical underpinnings and practical aspects of speech communication.
Another central aspect of the modeling is the relationship between human learning and computational methods trying to characterize the process. According to the present understanding, human language learning is largely driven by the interaction of statistical regularities in the sensory input available to the learner (e.g., Maye et al. [2002], Saffran et al. [1996], Saffran and Kirkham [2018], Werker and Tees [1984]), innate mechanisms, constraints, and biases for perception and learning from such input, and other mechanisms responsible for social, communicative and exploratory needs of the learner. By extracting the statistical regularities from their sensorimotor linguistic enviroment, children are capable of learning any of the world’s languages while fundamentally sharing the same basic cognitive mechanisms. A central topic in computational modeling of language acqusition is therefore to understand how much of language structure can be learned from the input data, and how much language-related prior knowledge needs to be built-in to the hard-coded mechanisms of these models. Note that human statistical learning is closely related to machine learning in computers, as both aim to extract statistical regularities from data using some sort of pre-specified learning principles. However, unlike standard speech technology systems such as automatic speech recognition, humans learners do not have access to data labels or consistent reward signals. For instance, a computational model of early infant word learning is essentially trying to find a solution to unsupervised pattern discovery problem: how to learn words from acoustic or multimodal input when there is no data labeling available. By applying a combination of speech processing and machine learning techniques to data representative of infant language experiences, explanation proposals for such a process can be created.
13.1.1. Computational modeling versus cognitive computationalism#
Note that computational modeling and representations often studied in the models should not be confused with classical computationalism. The latter is loaded with certain assumptions regarding the nature of the entities processed by the computational system (e.g., content of the representations, symbols) and what are the basic computational operations (e.g., symbol manipulation using Turing machines). In contrast, computational models are simply descriptions of the studied process in terms of the described assumptions, inputs, outputs, and processing mechanisms without prescribing further meaning to the components (unless otherwise specified). For instance, representations of typical DSP and machine-learning -based models can simply be treated as quantifiable states, such as artificial neuron/layer activations, posterior distributions, neural layer weights, distribution parameters. In other words, the representations are scalars, vectors, or matrices that are somehow causally related to the inputs of the system. Behavior of these representations can then be correlated and compared with theoretical concepts regarding the phenomenon of interest (e.g., comparing selectivity of neural layer activations towards known phoneme categories in the acoustic input to the model; see, e.g., Nagamine et al. [2015]) or comparing the overall model behavior to human behavior with similar input (e.g., Räsänen and Rasilo [2015]). As long as the models are able to explain the data or phenomena of interest, the models are a computational and hypothetical explanation to the phenomenon without loading the components with additional theoretical or philosophical assumptions. Additional theoretical loading comes from the data and evaluation protocols chosen to investigate the models and in terms of how the modeling findings are interpreted.
13.2. Role of computational models in scientific research#
Computational modeling has a role in scientific theory development and hypothesis testing by providing the means to test high-level theories of language processing with practical simulations (Fig. 2). This supports the more traditional approaches to language research that include collection of empirical data on human language processing, conducting brain research, or running controlled behavioral experiments in the laboratory or as real-world intervention studies. By implementing high-level conceptual models of language processing using real algorithms operating on real-world language data, one can test whether the models scale up to complexity of real-world sensory data accessible to human listeners. In addition to explaining already collected data on human language processing, computational models can also lead to new insights and hypotheses about the human processing to be tested in behavioral experiments.
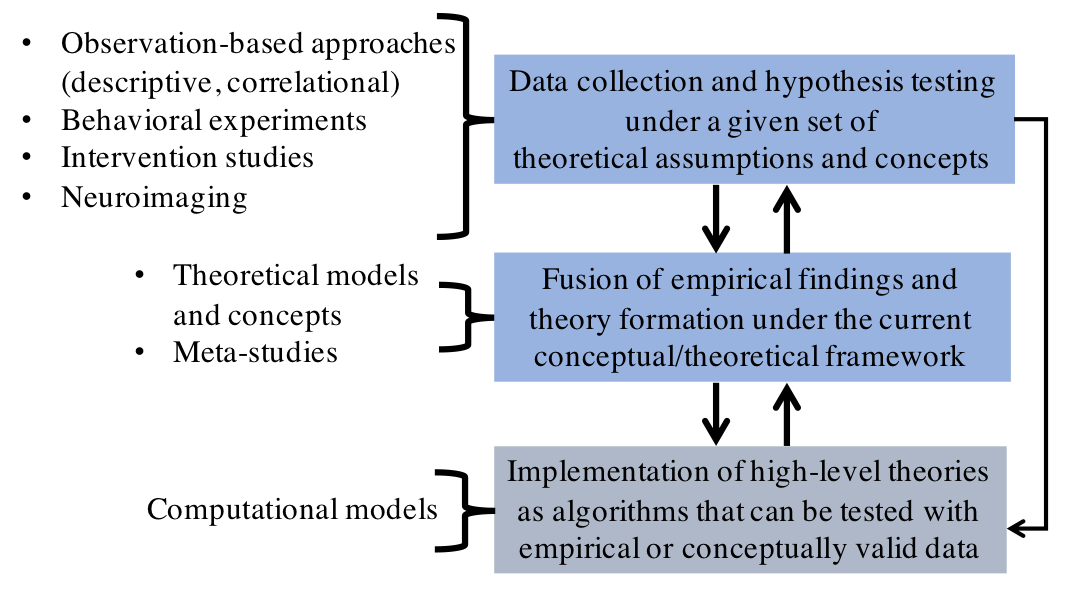 Figure 2:
Different aspects of human language processing research and how they
interact.
Figure 2:
Different aspects of human language processing research and how they
interact.
Computational modeling uses data from empirical research to test and
inform high-level theories related to the given topic.
One potential advantage of computational modeling is its capability to address multiple processing mechanisms and language phenomena simultaneously. This is since computational models can, and must, explicitly address all aspects of the information processing chain from input data to the resulting behaviour. By first formulating theories of language processing in terms of computational goals and operations, then implementing them as functional signal processing and machine learning algorithms, and finally exposing them to realistic sensory data comparable to what real humans experience, ecological plausibility and validity of the underlying theories can be explicitly tested (cf. Marr [1982]). In contrast, behavioral experiments with real humans—although necessary for the advancement of our scientific understanding and for general data collection—can usually focus on only one phenomenon at a time due to the need for highly-controlled experimental setups. The fragmentation of focus also makes it difficult to combine knowledge from individual studies into holistic theoretical frameworks (e.g., understanding how phonemic, lexical, and syntactic learning are dependent on each other in early language development).
13.3. Examples of computational modeling research#
Computational models of child language development: Computational
models of language learning aim at understanding how human children
learn to perceive and produce their native language. The basic idea is
to simulate the learning of a human child, either starting from “birth”
or from a specific stage of language development. Individual models
typically aim to answer questions such as: how phonemic categories are
learned, how word segmentation is achieved, how spoken words are
associated with their referential meanings, or how syntax can be
acquired? The grand challenge is to understand how the adult-like
understanding of language as a discrete, symbolic, and compositional
system can emerge from the exposure to noisy and inherently continuous
sensorimotor environment. Typical computational modeling research
questions include: 1) to what extent are languages learnable from the
statistics of sensory experiences, 2) what type of learning mechanisms
or constraints are needed for the process, and 3) what kind of and how
much data (“experiences”) are required in the process (quality and
quantity of speech, uni- vs. multimodal input etc.). A broader view
takes into account the fact that the children are not just passive
receivers of sensory information but can interact with their caregivers
and their environment as active explorers and learners. Therefore it is
also of interest 4) what type of additional interaction-related
mechanisms and dynamically created experiences are critical. The big
and yet unaswered question is what are the critical ingredients for
successful language learning, as all normally developing children with
very different language experiences, environments, and also somewhat
differing cognitive skills still manage to converge to a shared
communicative system of their native language.
As the short-term outcomes, models of language learning can test
and propose different hypotheses for different aspects of language
learning. They also produce functional algorithms for processing
acoustic or multimodal language data in low-resource settings, where
access to data labels is limited (e.g., Kakouros and Räsänen [2016], Kamper et al. [2017], Räsänen et al. [2018]). Long-term outcomes from language
acquisition modeling contribute to both basic science and practice. In
terms of basic science, the research tries to answer the question of how
one of the most advanced aspects of human cognition, i.e., language,
operates. Long-term practical goals include understanding the impact of
external factors in language development and how to ensure equally
supportive environments for children in different social settings,
understanding different types of language-related disorders and how to
best respond to them, but also how to develop autonomous AI systems
capable of human-like language learning and understanding without
supervised training, i.e.., development of systems ultimately capable of
understanding the intentions and meaning in communication.
Computational modeling of early language acquisition is closely
related to zero-resource speech processing (see
http://www.zerospeech.com/) that aims at algorithms capable of
unsupervised language learning from speech data.
Models of spoken word recognition: Another widely studied topic is
speech perception in adults. Computational models developed for this
purpose attempt to explain how the brain processes incoming speech in
order to recognize words in the input. Models in this area may focus on
explaining the interaction between sub-word and word-level units in
perception, on how words compete with each other during the recognition
process, or, e.g., on how the speech perception is affected by noise in
native and non-native listeners. Since word recognition is essentially a
temporal process, particular attention is typically paid to the
evolution of the recognition process as a function of time (or
proportion of input word or utterance perceived).
For an overview, see Weber and Scharenborg [2012]. For some examples
of models, see Magnuson et al. [2020], McClelland and Elman [1986], Norris [1994].
Models of speech production: This line of research attempts to
explain how human speech production works in terms of articulators and
their motor control. Some studies also focus on the acquisition of
speech production skills. Typical speech production models involve an
articulatory speech synthesizer—an algorithm capable
of producing audible speech signals by modeling the physical
characteristics of the vocal apparatus—and some type of motor control
algorithms that are responsible for phonation and articulator movements.
Sometimes hearing system is simulated as well. These models have various
uses from general understanding of the articulatory basis of speech to
understanding speech pathologies, articulatory learning in childhood or
adulthood, or special types of sound production such as singing.
For classical and more recent examples of articulatory models of
speech production, see, e.g., Birkholz [2005], Birkholz et al. [2015], Maeda [1988]. For models of infant learning of speech
production, see, e.g.,Howard and Messum [2014], Rasilo and Räsänen [2017], Tourville and Guenther [2011].
Multi-agent models of language learning, evolution and
communication: Languages are essentially cultural conventions based
on social activity, enabled by genetically coded cognitive and
physiological mechanisms, and learned through interactions between
people. One branch of computational modeling focuses on understanding
how languages emerge, evolve, and are learned through multi-agent
communication and interaction. These simulations, sometimes referred to
as language games or iterated learning (see Kirby [2002]), focus on
non-linear dynamical systems that result from the interaction of
multiple communicative computational agents. These agents can be purely
based on simulation, or they can be based on physical robots interacting
in a shared physical environment. By providing the agents with
different types of innate goals, mechanisms, learning skills and
environmental conditions, one can study the extent that language-like
signaling systems (as a social system) or language skills (as subjective
capabilities) can emerge from such conditions.
For overviews, see Kirby [2002], Steels [1997].
13.4. References and further reading#
Birkholz, P.: VocalTractLab: http://www.vocaltractlab.de/ [for work on articulatory synthesis]
Dupoux, E. et al.: Zero Resource Speech Challenge: http://www.zerospeech.com/ [a challenge on unsupervised speech pattern learning]
Peter Birkholz. 3D-Artikulatorische Sprachsynthese. PhD thesis, der Universität Rostock, 2005. URL: https://www.vocaltractlab.de/publications/birkholz-2005-dissertation.pdf.
Peter Birkholz, Lucia Martin, Klaus Willmes, Bernd J Kröger, and Christiane Neuschaefer-Rube. The contribution of phonation type to the perception of vocal emotions in german: an articulatory synthesis study. The Journal of the Acoustical Society of America, 137(3):1503 – 1512, 2015. URL: https://doi.org/10.1121/1.4906836.
Emmanuel Dupoux. Cognitive science in the era of artificial intelligence: a roadmap for reverse-engineering the infant language-learner. Cognition, 173:43 – 59, 2018. URL: https://doi.org/10.1016/j.cognition.2017.11.008.
William Havard, Laurent Besacier, and Olivier Rosec. Speech-coco: 600k visually grounded spoken captions aligned to mscoco data set. arXiv preprint arXiv:1707.08435, 2017. URL: https://doi.org/10.21437/GLU.2017-9.
Ian S Howard and Piers Messum. Learning to pronounce first words in three languages: an investigation of caregiver and infant behavior using a computational model of an infant. PLoS One, 9(10):e110334, 2014. URL: https://doi.org/10.1371/journal.pone.0110334.
Sofoklis Kakouros and Okko Räsänen. 3PRO – an unsupervised method for the automatic detection of sentence prominence in speech. Speech Communication, 82:67 – 84, 2016. URL: https://doi.org/10.1016/j.specom.2016.06.004.
Herman Kamper, Aren Jansen, and Sharon Goldwater. A segmental framework for fully-unsupervised large-vocabulary speech recognition. Computer Speech & Language, 46:154 – 174, 2017. URL: https://doi.org/10.1016/j.csl.2017.04.008.
Simon Kirby. Natural language from artificial life. Artificial life, 8(2):185 – 215, 2002. URL: https://doi.org/10.1162/106454602320184248.
Shinji Maeda. Improved articulatory models. The Journal of the Acoustical Society of America, 84(S1):S146 – S146, 1988. URL: https://doi.org/10.1121/1.2025845.
James S Magnuson, Heejo You, Sahil Luthra, Monica Li, Hosung Nam, Monty Escabi, Kevin Brown, Paul D Allopenna, Rachel M Theodore, Nicholas Monto, and others. EARSHOT: a minimal neural network model of incremental human speech recognition. Cognitive science, 44(4):e12823, 2020. URL: https://doi.org/10.1111/cogs.12823.
David Marr. Vision: A computational investigation into the human representation and processing of visual information. W.H. Freeman and Company, 1982.
Jessica Maye, Janet F Werker, and LouAnn Gerken. Infant sensitivity to distributional information can affect phonetic discrimination. Cognition, 82(3):B101 – B111, 2002. URL: https://doi.org/10.1016/S0010-0277(01)00157-3.
James L McClelland and Jeffrey L Elman. The TRACE model of speech perception. Cognitive psychology, 18(1):1 – 86, 1986. URL: https://doi.org/10.1016/0010-0285(86)90015-0.
Tasha Nagamine, Michael L Seltzer, and Nima Mesgarani. Exploring how deep neural networks form phonemic categories. In Sixteenth Annual Conference of the International Speech Communication Association. 2015. URL: https://www.isca-speech.org/archive_v0/interspeech_2015/papers/i15_1912.pdf.
Dennis Norris. Shortlist: a connectionist model of continuous speech recognition. Cognition, 52(3):189 – 234, 1994. URL: https://doi.org/10.1016/0010-0277(94)90043-4.
Pierre-Yves Oudeyer, George Kachergis, and William Schueller. Computational and robotic models of early language development: a review. In J.S. Horst and J. von Koss Torkildsen, editors, International handbook of language acquisition. Routledge/Taylor & Francis Group, 2019. URL: https://psycnet.apa.org/doi/10.4324/9781315110622-5.
Heikki Rasilo and Okko Räsänen. An online model for vowel imitation learning. Speech Communication, 86:1 – 23, 2017. URL: https://doi.org/10.1016/j.specom.2016.10.010.
Okko Räsänen. Computational modeling of phonetic and lexical learning in early language acquisition: existing models and future directions. Speech Communication, 54(9):975 – 997, 2012. URL: https://doi.org/10.1016/j.specom.2012.05.001.
Okko Räsänen, Gabriel Doyle, and Michael C Frank. Pre-linguistic segmentation of speech into syllable-like units. Cognition, 171:130 – 150, 2018. URL: https://doi.org/10.1016/j.cognition.2017.11.003.
Okko Räsänen and Heikki Rasilo. A joint model of word segmentation and meaning acquisition through cross-situational learning. Psychological review, 122(4):792, 2015. URL: https://psycnet.apa.org/doi/10.1037/a0039702.
Jenny R Saffran, Richard N Aslin, and Elissa L Newport. Statistical learning by 8-month-old infants. Science, 274(5294):1926 – 1928, 1996. URL: https://doi.org/10.1126/science.274.5294.1926.
Jenny R Saffran and Natasha Z Kirkham. Infant statistical learning. Annual review of psychology, 69:181 – 203, 2018. URL: https://doi.org/10.1146/annurev-psych-122216-011805.
Luc Steels. The synthetic modeling of language origins. Evolution of communication, 1(1):1 – 34, 1997. URL: https://doi.org/10.1075/eoc.1.1.02ste.
Jason A Tourville and Frank H Guenther. The DIVA model: a neural theory of speech acquisition and production. Language and cognitive processes, 26(7):952 – 981, 2011. URL: https://doi.org/10.1080/01690960903498424.
Andrea Weber and Odette Scharenborg. Models of spoken-word recognition. Wiley Interdisciplinary Reviews: Cognitive Science, 3(3):387 – 401, 2012. doi:10.1002/wcs.1178.
Janet F Werker and Richard C Tees. Cross-language speech perception: evidence for perceptual reorganization during the first year of life. Infant behavior and development, 7(1):49 – 63, 1984. URL: https://doi.org/10.1016/S0163-6383(84)80022-3.