6.1. Subjective quality evaluation#
In speech processing applications where humans are the end-users, there humans are also the ultimate measure of performance and quality. Subjective evaluation refers to evaluation setups where human subjects measure or quantify performance and quality. From a top-level perspective, the task is simple; subjects are asked to evaluate questions such as
Does X sound good?
How good does X sound?
Does X or Y sound better?
How intelligible is X?
However, like always, the devil is in the details. Subjective evaluation must be designed carefully such that questions address information which is useful for measuring performance and such that information extracted is reliable and accurate.
Most commonly, subjective evaluation in speech and audio refers to perceptual evaluation of sound samples. In some cases, evaluation can also involve interactive elements, such as participation in a dialogue over a telecommunication connection. In any case, perceptual evaluation refers to evaluation through the subjects’ senses, which in this context refers primarily to hearing. In other words, in a typical experiment setup, subjects listen to sound samples and evaluate their quality.

Photo by Anthony Brolin on Unsplash
6.1.1. Aspects of quality#
Observe that the appropriate evaluation questions are tightly linked to the application and context. For example, when designing a teleconferencing system for business applications, we are interested in entirely different types and aspects of quality than in the design of hearing-aids.
From a top-level perspective, we discuss quality, for example, with respect to
sound or speech quality, relating to an intrinsic property of the audio signal,
interaction and communication quality, as the experience of quality in terms of dynamic interaction,
service quality and user experience, which is usually meant to include beyond sound and interaction quality, the whole experience of using a service or device, including responsiveness of the system, network coverage, user interface, visual and tactual design of devices etc.
6.1.1.1. Sound and speech quality#
The acoustic quality of the signal can be further described for example, through concepts such as
noisiness or the amount of noise the speech signal is perceived to have (perceptually uncorrelated noise)
distortion describes how much parts of the speech signal are destroyed (perceptually correlated noise), though often also uncorrelated noises are referred to as distortions
intelligibility is the level to which the meaning of the speech signal can be understood
listening effort refers to the amount of work a listener has to use in listening to the signal and how much listening fatigue and annoyance a user experiences
pleasantness describes how much the speech signal annoys the listener
resemblance describes how close the speech signal is to the original signal
naturalness describes how natural an artificial speech source sounds, often used as a last resort when no other adjective feels suitable, then we can see that “It sounds unnatural”.
acoustic distance or how near or far the far-end speaker is perceived to be, which is closely related to the amount of reverberation the signal has (and how much delay the communication path has)
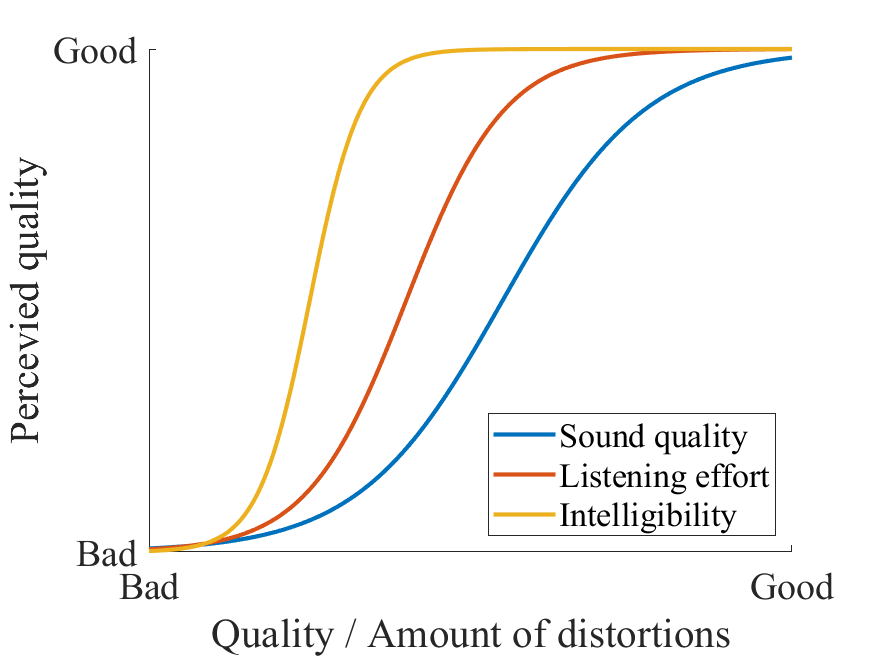
Note that we can also think of intelligibility and listening efforts as separate aspects of sound quality. That is, we can perceive noisiness and distortions, but still not be annoyed by the quality at all and be able to listen to the sound effortlessly. Listening effort is usually a prerequisite for loss of intelligibility; if we have to listen carefully then it is exhausting in the long run. Quality, effort and intelligibility is, in this sense, addressing different quality levels, where intelligibility is an issue only at very bad quality, effort in the middle range, whereas quality is always relevant (see figure on the right).
6.1.1.2. Interaction quality#
The quality of interaction when using speech technology can be further described, for example, through concepts such as
delay describes the delay between the acoustic event at the speaker’s end, to the time the event is perceived at the receiving end. It is further divided into algorithmic delay caused by processing, as well as delays caused by the transmission path.
echo is the feedback loop of sound in the sound system, where a sound loudspeaker is picked by a microphone
presence or distance is the feeling of proximity (and intimacy) that a user experiences in communication
naturalness can also here be used to describe communication with the obvious meaning.
6.1.2. Choosing subjects - Naïve or expert?#
When designing a subjective listening test, one of the first important choices is whether listeners are naïve or expert. With naïve listeners, we refer to people with neither prior experience in analytic listening, nor other related expertise. Expert listeners are then, obviously, subjects who are trained in the art of listening and have the ability to analytically evaluate small differences in sound samples. Good expert listeners are typically researchers in the field with years of experience developing speech and audio processing and listening to sound samples. Some research labs even have their own training for expert listeners.
Expert listeners are the best listeners because they can give accurate and repeatable results. They can hear the smallest audible differences, and they can grade the differences consistently. In other words, if an expert hears the same sounds in two tests, he or she can give them exactly the same score both times and (in an ideal world) his or her expert colleagues will grade the sounds similarly. However, the problem is that expert listeners have skills far beyond those of the average user of speech and audio products. If we want average users to enjoy our products, then we should be measuring the preferences of average users. It is uncertain whether the preferences of expert listeners align with average users. For example, expert listeners might notice a highly annoying distortion that an average user never discovers. The expert would, therefore, be unable to enjoy a product though it is great for the average user.
Naïve listeners are, therefore, the best listeners in the sense that they reflect best the preferences of the average population. The downside is that since naïve listeners do not have experience in subjective evaluation, their answers usually have a high variance (the measurement is noisy). That is, if they hear the same samples twice, they are often unable to repeat the same grade (intra-listener variance), and the difference in grades between listeners is often high (inter-listener variance). Consequently, to get useful results from naïve listeners, you need a large number of subjects. To get statistically significant results, you often need a minimum of 10 expert listeners, whereas you frequently need more than 50 naïve listeners. The difficulty of the task naturally can have a large impact on the required number of subjects (difficult tasks require a larger number of listeners for both expert and naïve listeners).
Note that the above definition leaves a large grey area between naïve and expert listeners. A naïve listener loses the naïve status when participating in a listening test. However, a naïve listener needs years of training to become an expert listener. This is particularly problematic in research labs, where there are plenty of young researchers available for listening tests. They are not naïve listeners anymore, but they need training to become expert listeners. A typical approach is then to include the younger listeners regularly in listening tests, but remove those listeners in post-screening if their inter- or intra-listener variance is too large. That way the listeners slowly gain experience, but their errors do not get too much weight in the results. This approach however has to be very clearly monitored such that it does not lead to tampering of results (i.e. scientific misconduct). Any listeners removed in post-screening and the motivations for post-screening have to therefore be documented accurately.
6.1.3. Experimental design#
To get accurate results from an experiment, we have to design the experiment such that it matches the performance qualities we want to quantify. For example, in an extreme case, an evaluation of the performance of noise reduction can be hampered, if a sound sample features a speaker whose voice is annoying to the listeners. The practical questions are however more nuanced. We need to consider for example:
To what extent does the language of speech samples affect listening test results? Can naïve listeners accurately grade speech samples in a foreign language? Does the text content of speech samples affect grading: for example, if the spoken text is politically loaded, would the grades of politically left- and right-leaning subjects give different scores?
Does the text material, range of speakers, and recording conditions reflect the target users and environments? For example, if we test a system with English-speaking listeners with speech samples in English, do the results reflect performance for Chinese users? Are all phonemes present in the material and do they appear equally often as they do in the target languages? Does the material feature background noises and room acoustics in the same proportion as real-world scenarios? Does the gender of the speaker or listener play a role? Or their cultural background?
Is the subject learning from previous sounds, such that the answers regarding the current sound being different from the previous sound? That is if the subject hears the same sound with different distortions several times, then he already knows how the sound is supposed to sound like. Then perhaps he evaluates distortions differently, because he knows how the sound is supposed to sound like.
To take into account such considerations, experiments can be designed in different ways, for example:
We can measure absolute quality (How good is X?), or relative quality (How good is X in comparison to Y?) or we can rank samples (“Which one is better, A or B?” or “Order samples A, B, and C from best to worst.”). Clearly absolute quality is often the most important quality for users since users usually do not have the opportunity to test products side by side. However, for example during development, two versions of an algorithm could have very similar quality, such that it would be difficult to determine preference with an absolute quality measure. Relative quality measures then give more detailed information, explicitly quantifying the difference in performance. Ranking samples are usually used in competitions, for example, when a company wants to choose a supplier for a certain product, it is then useful to be able to measure the ordering of products. It is thus more refined than relative measures in terms of finding which one is better, but at the same time, it does not say how large the difference is between particular samples.
In many applications, the target is to recover a signal after transmission or from a noisy recording. The objective is thus to obtain a signal which is as close as possible to the original signal. It can then be useful to play the original signal to subjects as a reference, such that they can compare performance explicitly with the target signal. While this then naturally gives listeners the opportunity to make more accurate evaluations, it is also not realistic. In real life, we generally do not have access to the original; for example, when speaking on the phone, we cannot directly hear the original signal but can hear only the transmitted signal. We would therefore never be able to compare performance to the target, but only absolute quality.
In some cases, it is also possible that some speech enhancement methods improve quality such that the output sounds better than the original non-distorted sound!In some experimental designs, the subject can listen to sounds many times, even in a loop. That way we make sure that the subject hears all the minute details. However, that is unrealistic since in a real scenario, like a telephone conversation, you usually can hear sounds only once. Repeated sounds are therefore available only for expert listeners.
In the choice of samples, the length of samples should be chosen with care. Longer samples reflect better real-life situations, but bring many problems, for example:
The ability of listeners to remember particular features of the sound, especially in comparison to other sounds, is very limited. Long samples can thus reduce the accuracy of results.
Longer samples can have multiple different characteristics, which would warrant a different score. The listener would then have to perform a judgement; which part of the sentence or sample is more important, and which type of features are more important for quality? This can lead to ambiguous situations.
Listening to very short samples can, in turn, make features of the sound audible, which a listener could not hear in a real-life setting.
Usually, we prefer to have speech samples in the same language as the listeners. With expert listeners, this constraint might not be so strict, but this is scientifically uncharted territory.
Speech samples should generally be phonetically balanced “nonsense” sentences. With phonetically balanced, we refer to sentences where all phonemes appear with the same frequency as they appear on average in that particular language. With nonsense sentences, we refer to text content that does not convey any particular, loaded, or surprising meaning. For example, “An apple on the table” is a good sentence in the sense that it is grammatically correct and there is nothing strange with it. Examples of bad sentences would be “Elephants swimming in champagne”, “Corporations kill babies” and “The dark scent of death and mourning”.
When playing samples to subjects, they will both learn more about the samples, but also experience fatigue. Especially for naïve listeners, the performance of subjects will therefore change during an experiment. It is very difficult to take such changes in performance into account in analysis and it is therefore usually recommended to randomize the ordering of samples separately for each listener. That way the effects of learning and fatigue will be dispersed evenly across all samples, such that they have a uniform effect on all samples.
To measure the ability of listeners to consistently grade samples, it is common and good practice to include items in the test whose answers are known. Unexpected results with such samples can then be used to spot and exclude problematic listeners from the pool of listeners. For example, we can
repeat a sample twice, such that we measure the listeners ability to give the same grade twice,
have the original reference signal hidden among test samples (known as the hidden reference), such that we can measure the listeners ability to give the perfect score to the perfect sample,
include samples with known distortions among the test items, such that we can compare results with prior experiments that included the same known samples. Typically such known distortions include, for example, low-pass filtered versions of the original signal. Such samples are known as anchors and low and high-quality anchors are then respectively known as low-anchor and high-anchor.
6.1.4. Some use cases#
During research and development of speech and audio processing methods, researchers have to evaluate the performance of their methods. Most typically such evaluations are quite informal; when you get output from a new algorithm, the first thing to do is to listen to the output - is it any good? In some stages of development, such evaluations are an ongoing process; tweak a parameter and listen to how it affects the output. In early development, listening is in practice, also a sanity check; programming errors often cause bad distortions in the output, which can be caught by listening.
When publishing results and at later stages of development, it is usually necessary to evaluate quality in a more formal manner. The engineer developing an algorithm is not a good listener, because he has extremely detailed knowledge about the performance and could often spot his or her own method, from a set of sound samples. The developer is therefore biased and not a reliable listener.
Therefore, when publishing results we need reproducible experiments in the sense that if another team would repeat the listening experiment, then they could draw the same conclusions. Listening tests therefore have to have a sufficient number of listeners (expert or naïve) such that the outcome is statistically significant (see Analysis of evaluation results).When selecting a product among competing candidates we would like to make a good evaluation. The demands are naturally very different depending on the scenario; 1) if you want to choose between Skype, Google and Signal for your personal VoIP calls during a visit abroad, you are probably content with informal listening. 2) If on the other hand, you are an engineer and assigned to the task of choosing a codec for all VoIP calls within a multi-national company, then you probably want to do a proper formal listening test.
Monitoring quality of in-production system; The quality of a running system can abruptly or gradually change due to bugs and equipment failures, including memory errors. To detect such errors, we need to monitor quality. Often such monitoring is based on automated objective tests.
6.1.5. Frequently used standards and recommendations for quality evaluation#
6.1.5.1. Expert listeners#
By far the most commonly used standard applied with expert listeners is known as MUSHRA, or MUltiple Stimuli with Hidden Reference and Anchor, defined by ITU-R recommendation BS.1534-3. It offers a direct comparison of multiple target samples, with a reference signal, hidden reference, and anchor. Users can switch between samples on the fly and many interfaces also allow looping short segments of the signal.
Each sample is rated on an integer scale 1-100.
MUSHRA is very useful for example when publishing results, because it is simple to implement and well-known. Open source implementations such as webMUSHRA are available.
Practical experience has shown that MUSHRA is best applied for intermediate-quality samples, where a comparison of 2-5 samples is desired. Moreover, a suitable length of sound samples ranges from 2 to approximately 10 seconds. Furthermore, if the overall length of a MUSHRA test is more than, say, 30 minutes, then the fatigue of listeners starts to be a significant problem. With 10 good listeners, it is usually possible to achieve statistically significant results, whereas 6 listeners can be sufficient for informal tests (e.g. during testing). These numbers should not be taken as absolute but as practical guidance to give a rough idea of what makes a usable test.
MUSHRA is however often misused by omitting the anchors; a valid argument for omitting anchors is that if the distortions in the target samples are of a very different type than the typical anchors, then anchors do not provide any added value. Still, such omissions are not allowed by the MUSHRA standard.For very small impairments in audio quality, Recommendation ITU-R BS.1116-3 (ABC/HR) is recommended instead of MUSHRA (see https://www.itu.int/rec/R-REC-BS.1116-3-201502-I/en).
6.1.5.1.1. Demo#
Below is a greatly simplified example of a MUSHRA test. It is intended to give an impression of such testing, but it is missing several features of a standard test. Most importantly, 1) it does not allow looping of the whole or a part of samples, and 2) it is missing the anchors though a hidden reference is included.
Your task (the listeners’ task) is to compare the different items to the reference and score them (0=bad, 100=perfect).
Show code cell source
import ipywidgets as widgets
import IPython
import numpy as np
item_num = 5
path = 'sounds/'
item_names_original = ['sp02.wav',
'sp02_street_sn0.wav',
'sp02_street_sn5.wav',
'sp02_street_sn10.wav',
'sp02_street_sn15.wav',
'sp02.wav'
]
# randomize noisy samples
permutation = np.array(np.random.permutation(item_num)+1).astype(int)
item_names = item_names_original[0:1] + [item_names_original[item] for item in permutation]
item_labels = ['Reference'] + [f"Item {item}" for item in range(1,item_num)]
sliders = [ widgets.IntSlider(value=0,
min=0,
max=100,
step=1,
description=item_labels[item],
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d')
for item in range(item_num)]
IPython.display.display(IPython.display.HTML("Reference"))
IPython.display.display(IPython.display.Audio(path + item_names[0]))
for item in range(1,item_num):
display(sliders[item])
IPython.display.display(IPython.display.Audio(path + item_names[item]))
Above sound examples are from the NOIZEUS corpus [Hu and Loizou, 2007].
For further (and better) illustrations and examples of the MUSHRA test, see https://www.audiolabs-erlangen.de/resources/webMUSHRA
6.1.5.2. Naïve listeners#
P.800 is the popular name of a set of listening tests defined in the standard ITU-TRecommendation P.800 “Methods for subjective determination of transmission quality”. It is intended to be a test that gives as realistic results as possible by assessing performance in setups that resemble real use cases. The most significant consequences are that P.800 focuses on naïve listeners, and since telecommunication devices are typically hand-held over one ear, P.800 mandates tests with headphones, which are held only on one ear. To make the test simpler for naïve listeners, P.800 most typically uses an integer scale 1-5 known as mean opinion score (MOS). Each grade is given a characterization such as
Rating |
Label |
|---|---|
1 |
Excellent |
2 |
Good |
3 |
Fair |
4 |
Poor |
5 |
Bad |
This makes the ratings more concrete and easier for users to understand. A downside of labelling the ratings is that such labels are specific to each language, and the MOS scores given in different languages might thus not be directly comparable. Who is to know whether excellent, erinomainen, ممتاز, and маш сайн mean exactly the same thing? (Those are English, Finnish, Arabic, and Mongolian, in case you were wondering.)
P.800 is further split into
Conversation opinion tests, where participants grade the quality after using* a telecommunication system for a conversation. Typically, the question posed to participants is “Opinion of the connection you have just been using: Excellent, God, Fair, Poor, Bad.” An alternative is “Did you or your partner have any difficulty talking or hearing over the connection? Yes/No.”
Listening opinion tests, where participants grade the quality after listening to the output of a telecommunication system.
The grading of listening opinion tests can, more specifically, be one of the following:
Absolute category rating (ACR), where the above MOS scale is used to answer questions like “How good is system X?”
Show code cell source
import ipywidgets as widgets
import IPython
import numpy as np
path = 'sounds/'
item_name = 'sp01_airport_sn5.wav'
IPython.display.display(IPython.display.HTML("P.800 ACR: "))
IPython.display.display(IPython.display.Audio(path + item_name))
display(widgets.RadioButtons(
options=['Excellent','Good','Fair','Poor','Bad'],
description='How good is this sample?',
disabled=False))
IPython.display.display(IPython.display.HTML("<b>Note: In real P.800 tests, samples are played only once.</b>"))
Above sound examples are from the NOIZEUS corpus [Hu and Loizou, 2007].
Degradation category rating (DCR), where the objective is to evaluate the amount of degradation caused by some processing. Samples are presented to listeners by pairs (A-B) or repeated pairs (A-B-A-B) where A is the quality reference and B is the degraded sample. Rating labels can be for example
Rating |
Label |
|---|---|
1 |
Degradation is inaudible |
2 |
Degradation is audible but not annoying |
3 |
Degradation is slightly annoying |
4 |
Degradation is annoying |
5 |
Degradation is very annoying |
Show code cell source
import ipywidgets as gadgets
import IPython
import numpy as np
path = 'sounds/'
item_names = ['sp05_car_sn15.wav',
'sp05_car_sn10.wav']
IPython.display.display(IPython.display.HTML("P.800 DCR: "))
IPython.display.display(IPython.display.HTML("Sample A "))
IPython.display.display(IPython.display.Audio(path + item_names[0]))
IPython.display.display(IPython.display.HTML("Sample B "))
IPython.display.display(IPython.display.Audio(path + item_names[1]))
display(widgets.RadioButtons(
options=['Degradation is inaudible',
'Degradation is audible but not annoying',
'Degradation is slightly annoying',
'Degradation is annoying',
'Degradation is very annoying'],
description='How much worse is sample B than sample A?',
disabled=False))
IPython.display.display(IPython.display.HTML("<b>Note: In real P.800 tests, samples are played only once.</b>"))
Above sound examples are from the NOIZEUS corpus [Hu and Loizou, 2007].
Comparison category rating (CCR), is similar to DCR, but such that the processed sample B can be also better than A. Rating labels can then be for example
Rating |
Label |
|---|---|
3 |
Much better |
2 |
Better |
1 |
Slightly better |
0 |
About the same |
-1 |
Slightly worse |
-2 |
Worse |
-3 |
Much worse |
P.804 Subjective diagnostic test method for conversational speech quality analysis
P.805 Subjective evaluation of conversational quality
P.806 A subjective quality test methodology using multiple rating scales
P.807 Subjective test methodology for assessing speech intelligibility
P.808 Subjective evaluation of speech quality with a crowdsourcing approach
P.835 Subjective test methodology for evaluating speech communication systems that include noise suppression algorithm
And many more, see https://www.itu.int/rec/T-REC-P/en
Holding a phone on one ear
 Photo by
Fezbot2000 on Unsplash
Photo by
Fezbot2000 on Unsplash
6.1.6. Intelligibility testing#
When a speech signal has been corrupted by a considerable level of noise and/or reverberation, its intelligibility starts to deteriorate. We might misinterpret or -understand words or entirely miss them. Observe that the level of distortion is quite a bit higher than what we usually consider in quality tests.
Typically we have to choose between correctly interpreted words or phonemes/characters. For example, if the sentence is
How to recognize speech?
and what we hear is
How to wreck a nice beach?
then we can count correct words for example as
How to recognize speech?
How to wreck a nice beach?
S I I S
where we use the notation S - substitution, I - insertion, D - deletion. The word error rate would then be
where \(N\) is the total number of words. In the above example, we thus have WER = 100%.
If we go character by character, then instead we would have
How to rec..og.nize speech
How to wreck a nice beach
I SI S DS S
Here we would then define the character error rate as
where \(N\) is the total number of characters. The value in the above example would then be 33%.
It is clear that the word error rate is thus much more strict than the character error rate. A single incorrect character will ruin a word, while the character error rate is affected much less. WER is much easier to compute than the CER and also leads to fewer ambiguous situations. It is however dependent on the application which measure is better suited.
Observe that both word and error rates are applicable as both objective measures, in speech recognition experiments, as well as a subjective measure, where human subjects evaluate the quality of sounds.