2.3. Linguistic structure of speech#
2.3.1. Overview#
Besides their acoustic characteristics, speech signals can be characterized in terms of their linguistic structure. Linguistic structure refers to the recurring regularities in spoken language as described by linguistic theories, such as what are the basic building blocks of speech and how they organized. Linguistic descriptions provide a means for systematic interpretation, conceptualization, and communication of speech-related phenomena.
Many linguistic properties of speech, such as syllables and words, also have their analogs in written language. However, it is important to distinguish the two from each other: While written language consists of discrete categorical elements (sequences of letters, whitespaces, and punctuation marks), speech signals are always continous and non-categorical. This is due to the motor behavior in speech production, which operates in real-time and finite speed under physical and neurophysiological constraints. Therefore, the resulting speech signal also flows in continuous time and frequency. In addition, where speech carries extra information in terms of how things are said and what are the characteristics of the speaker, written language is impoverished of these aspects. In contrast, written language uses lexical and syntactic means and special characters (and more recently, emoticons) to differentiate more fine-grained meanings, such as conveying emotional content or differentiating questions from statements. Finally, only few languages have clear one-to-one relationship between how words are pronounced and how they are written. Therefore, a separate system is needed to describe structure of spoken language, and one should not equate units of written language to that of a spoken one by default. Naturally, the two have a systematic relationship in order to enable reading and writing. However, this relationship also varies from language to another.
Within the broad field of linguistics, phonetics is its branch that focuses on understanding the physical basis of speech production, speech signals, and speech perception. In contrast, phonology is a branch of linguistics that studies sound systems of languages (both spoken and signed). While both attempt to describe how spoken language is organized, phonetic description attempts to be faithful to the acoustic, articulatory and auditory aspects of the speech signal. Phonetics are therefore strongly grounded to the measurable phenomena in the physical world. In contrast, phonological description consists of abstract speech units that allow more convenient study of how sounds of a language combine to create meaningful messages. For this, phonological description usually gets rid of signal variation that does not impact meaning of the speech. To give an example, different speakers of the same language may use different pronunciations of the same word, still resulting in the same phonological form. In contrast, accurate phonetic description would reflect the pronunciation-dependent differences, allowing documentation and study of such differences. Since speech processing is primarily concerned with physical (digitized) speech signals and how to deal with them, we will use phonetics as the primary language of description. However, the basic relationship between phonetic and phonological units is also briefly discussed below.
2.3.2. Elementary units of spoken language#
In terms of basic phonetic organization, speech can be seen as a hierarchical organization of elementary units of increasing time-scale (Fig. 1). At the lowest level of hierarchy, there are phones, which are considered as physical realizations of more abstract phonemes. Sequences of phones are organized into syllables, and syllables make up words (where each word consists of one or more syllables). One or more words then make up utterances. Phones are sometimes referred to as segmental units, and speech phenomena, such as intonation, taking place at time-scales larger than individual phones are called as suprasegmental phenomena. In addition, speech is sometimes said to have so-called double articulation (aka. duality of patterning). This refers to the fact that meaningful units of speech (words, utterances) consist of non-meaningful units (phones/phonemes) that still signify distinctions in meaning. At all levels, units and their relative organization are language-dependent, such as which phones, syllables, and words are employed and how they are allowed to follow each other. However, there are also certain common tendencies (aka. linguistic universals) that result from restrictions in the speech production and perception apparati or due to other shared characteristics of natural languages.
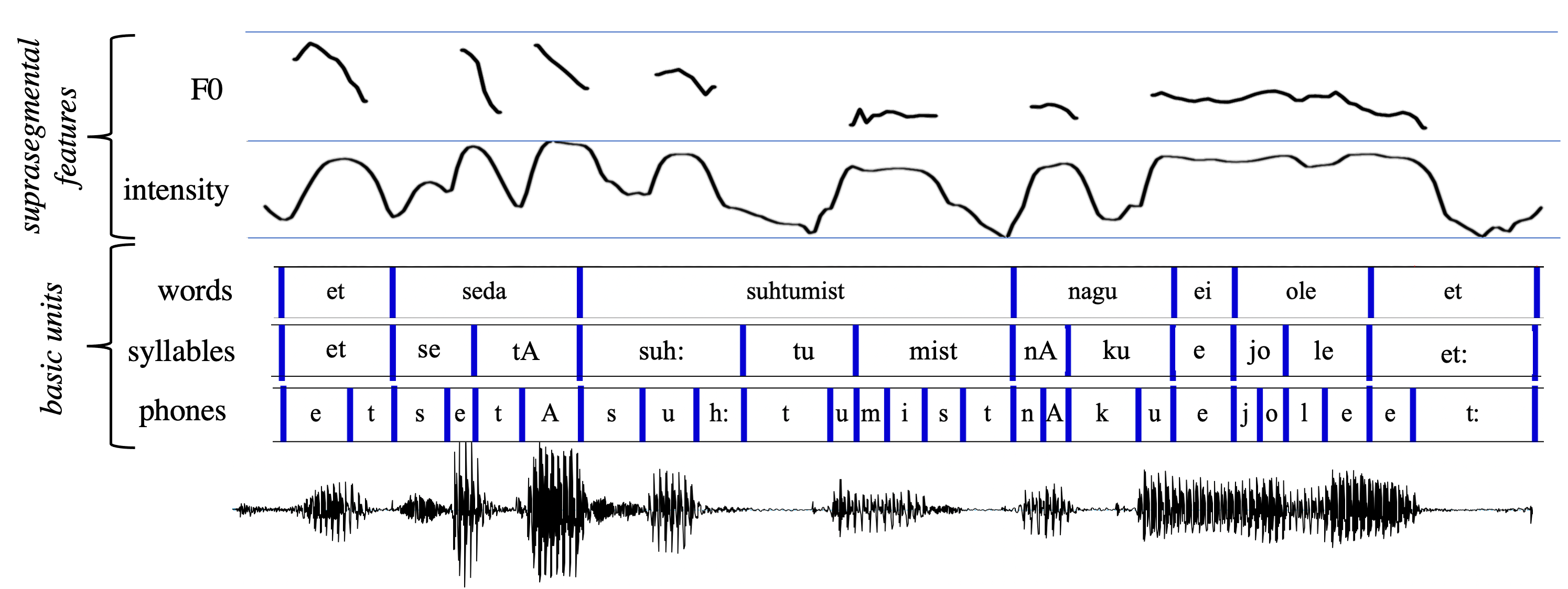 Fig. 1:
An example of the hierarchical organization of speech in terms of
phones, syllables, and words for an Estonian speech sample. Two
suprasegmental features, namely F0 and intensity, are also shown on top.
In this example, syllables are denoted in terms of their phonetic
constituents while words are represented orthographically. Example
annotations taken from Phonetic Corpus of Estonian Spontaneous Speech
(reproduced with permission) and represented in graphical form using
Praat.
Fig. 1:
An example of the hierarchical organization of speech in terms of
phones, syllables, and words for an Estonian speech sample. Two
suprasegmental features, namely F0 and intensity, are also shown on top.
In this example, syllables are denoted in terms of their phonetic
constituents while words are represented orthographically. Example
annotations taken from Phonetic Corpus of Estonian Spontaneous Speech
(reproduced with permission) and represented in graphical form using
Praat.
When discussing units of speech, it is often useful to distinguish unit types from unit tokens. Type refers to a unique unit category, such all [r] sounds belong to the same phone type. Token refers to an individual realization of a type. For instance, word “roar” has two [r] tokens in it.
2.3.2.1. Phones#
Phones are the elementary units of speech, associated with articulatory gestures responsible for producing them and with acoustic cues that make them distinct from other phones. Phonetic transcription is the process of marking down phones of speech with symbols (denoted with brackets [ ]). Phonetic transcription often makes use of the International Phonetic Alphabet (IPA). On a high level, phones can be divided into vowels (e.g., [a], [i], and [u]) and consonants (e.g., [p], [b], [s]). While all vowels are voiced sounds (see speech production), consonants can be voiced or unvoiced.
The primary determiner of vowel identity is position of the narrowest gap in the vocal tract (Fig. 2), as primarily controlled by tongue position in the mouth. Vowels can be categorized in terms of their openness/closeness (how wide is the narrowest part of the vocal tract between tongue and top of the mouth), and frontness/backness (how front/back is the tongue in the mouth). In additon, vowels with the same place of articulation can change depending on lip rounding (e.g., [o] versus [u]). Protrusion of lips during the rounding increases the effective length of the vocal tract, hence altering the resonance frequencies of the tract. A special vowel called “schwa” ([ə]) corresponds to an articulatory configuration, where jaw, lips, and tongue are completely relaxed, hence corresponding a central mid vowel.
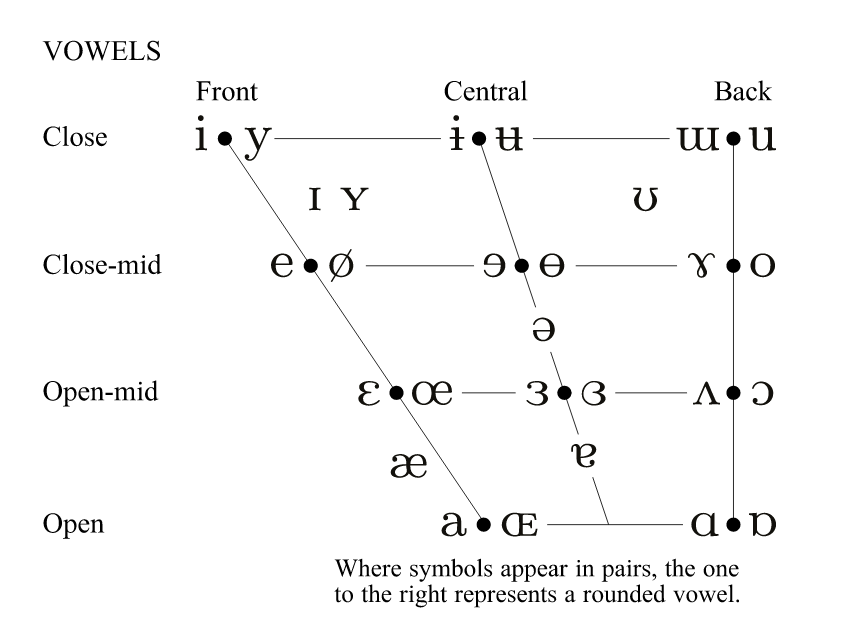 Fig. 2: IPA chart for vowels (reproduced by CC BY-SA 3.0)
Fig. 2: IPA chart for vowels (reproduced by CC BY-SA 3.0)
Consonants can be categorized in terms of their manner and place of articulation. Figure 3 shows IPA chart for consonants organized in terms of place of articulation (columns)and manner of articulation (rows).
Place of articulation refers to the point of tighest constriction in the vocal tract, as in vowels. However, in consonants, the gap at the place of constriction is smaller or the airflow in the tract is completely blocked for a period of time. In addition, the constriction can be created at different positions of the vocal tract using different articulators beyond the tongue, such as using lips, glottis, or uvula.
Manner of articulation refers to the manner that the constriction is created, including its temporal characteristics. For instance, plosives (e.g., unvoiced [k], [p] or voiced [g], [b]) consist of a complete blockage, aka. closure, of the vocal tract. This causes accumulation of air pressure in the tract before the blockage, which then results in as a noisy burst of airflow when the closure is released. Trill consonants, such as [r], consist of several rapid and subsequent closures of the tract caused by tongue vibrating against the oral cavity structures at the given place of articulation (e.g., tongue tip vibrating against alveolar ridge in [r]). Taps and flaps are similar to trills, but only consist of one quick closure and its release. Fricatives are turbulent sounds where the constriction is so narrow that the air flowing though it becomes turbulent. This turbulence causes the “hissing” sound characteristic of fricatives, such as in [s], [f], and [h] (e.g., as in “she” or “foam”). *Nasals *are sounds where the oral cavity has a complete closure, but the air can enter the nasal cavity through the velar port and exit through nostrils, adding another branch to the vocal tract with its own resonances and antiresonances (see also speech production). Approximants are sounds where articulators approach each other without becoming narrow enough to introduce turbulence to the sound. Among the approximants, glides are sounds similar to vowels, but act as syllable boundaries instead of syllabic nuclei (see below) typically with articulatory movement taking place throughout the sound (e.g., [y] as in “yes” or [w] in “water”). Lateral approximants consist of sounds where some part of the tongue touches the roof of the mouth but the air can flow freely from both sides of the tongue (e.g., [l] as in “love”). There are also other categories of consonants and ways to categorize them, and an interested reader is suggested to consult some phonetics textbook for more information.
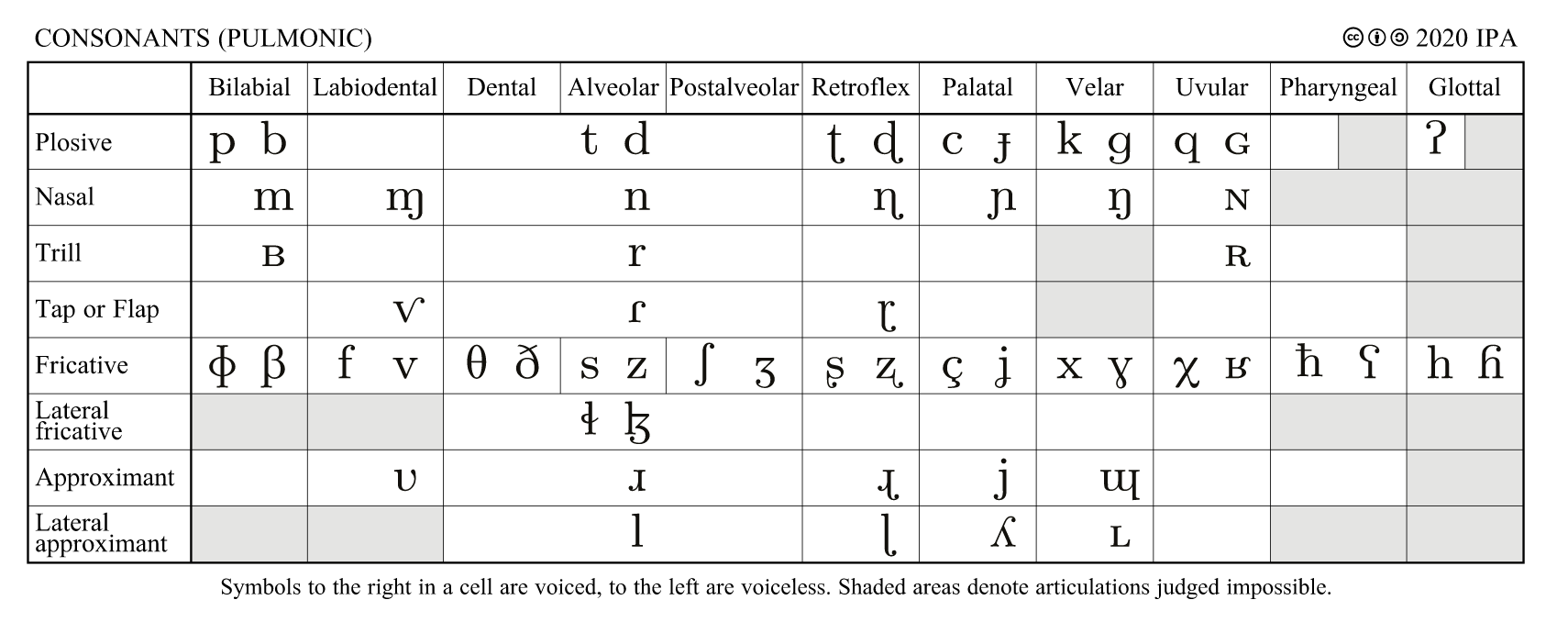 Fig.3: IPA chart for pulmonic consonants (reproduced by CC BY-SA
3.0).
Fig.3: IPA chart for pulmonic consonants (reproduced by CC BY-SA
3.0).
The majority of consonant sounds, including those reviewed above and listed in Fig. 3, are called pulmonic consonants. This means that the air flow (energy) for sound production originates from lung pressure, whether voiced or not. Besides the pulmonic sounds, some languages make use of non-pulmonic consonants. These can include implosives (plosives that are formed during inhalation of air), clicks (produced by subpressurized pockets of air between two concurrent closures that are then suddenly released), and ejectives (where the excitation energy for the sound is formed at the glottis by lowering the phrarynx, closing the glottis, and then raising the pharynx, resulting in increased air pressure in the tract while an obstruction is maintained at the place of articulation).
Coarticulation is an important speech phenomenon where realization of speech sounds is affected by the neighboring speech sounds. This is since articulatory gestures for speech production are almost always anticipating the production of the next sound (aka. anticipatory coarticulation) or still recovering their positions from the previous sound (aka. perseverative coarticulation). Since all articulators can only move with a finite speed from one articulatory configuration to another, coarticulation is present in virtually all observable speech beyond isolated vowels. Given that phones are the smallest sound units of a language, coarticulation can have a large effect on the acoustic form that phones take in actual continuous speech, introducing additional non-phonemic variability (see below) in the acoustical form of phones.
2.3.2.1.1. Phones vs. phonemes#
As mentioned above, phones are sounds of a language that have an articulatory, and thereby also acoustic, basis. Another commonly encountered basic unit of speech is a phoneme (denoted with slashes / /). Phonemes are defined in terms of their meaning contrasting function: two different phones of a language are also different phonemes, if they can change the meaning of a word. For example, consider words “cat” ([k] [ae] [t]) and “bat” ([b] [ae] [t]). In case of English, the initial [k] and [b] phones are also distinct phonemes /k/ and /b/, as they change the meaning of the otherwise identical word. Also note that [k] [ae] [t] and [b] [ae] [t] are so-called minimal pairs, as they only differ by one phoneme. A good rule of thumb is that phones are defined in terms of their articulatory or acoustic properties, whereas each phonemic category consists of all possible sounds that can be substituted for each other without affecting the meaning of any word in the given language.
Allophones are the alternative phones that all stand for the same phoneme in the given language. For instance, phones [r] and [l] can be considered as allophones of the same Japanese phoneme, as they can be used interchangeable in Japanese without affecting the communicated meanings. In English, [r] and [l] are not allophones, as they distinguish meanings (e.g., as in “lock” and “rock”). In fact, listeners tend to become worse in discriminating those non-native phonemic contrasts from each other that do not mark a phonemic contrast in their native language. This change in discrimination comes with language experience, and young infants start with the capability to discriminate both native and non-native contrasts (e.g., Werker & Tees, 1984).
2.3.2.2. Syllables#
The second unit in the “size hierarchy” of spoken language is a syllable. Syllables are sequences of sounds (one or more), consisting of a syllable nucleus (typically a vowel) and optional initial and final sound sequences, also known as onset and coda, respectively. Onsets and coda tend to have consonant sounds. Sometimes onset is separated from the rime, where the rime then consists of the nucleus and coda. Syllables can be considered as rhythmic units, as the alternation between consonants and vocalic syllabic nuclei give rise to the typical rhythmic patterns of different languages, as vowels generally have higher energy (are louder) than consonants. Concept of sonority sequencing principle (SSP) refers to this sequential alternation between less loud consonants and louder syllable nuclei. More specifically, in SSP, the first phone of syllable onset is supposed to be the least sonorous of the sounds preceding the syllable nucleus. Then the sonority increases towards the nucleus if more than one consonant exists in the onset. In the same manner, sonority of the consonants in the syllable coda (offset) decreases towards the end of the syllable. Sonority hierarchy determines the relative sonority (“loudness”) of different phones. As wikipedia states, “*typically they *[relative sonorities] are vowel > glide > liquid > nasal > obstruent (or > fricative > plosive > click)”.
Due to coarticulation that can have large impact on individual phone segments and due to rhythmic transparency of syllables, some authors consider syllables as more robust perceptual units of language than individual phones (e.g., Nusbaum & DeGroot, 1991), including also young children (see Hallé & Cristia, 2012, for an overview). In addition, children and illiterate listeners have better introspective access to syllabic structure of speech in contrast to underlying phonetic or phonemic constituents (Liberman et al., 1974; Morais et al., 1989). However, coarticulation has also effects across subsequent syllables, and human speech perception also makes use of cues beyond the time-scale of individual syllables. However, syllabic organization of speech is still central to understanding how speech is organized. Studies on conversational speech show that onset and nucleus of a syllable are much more central to succesful comprehension of speech, and hence also produced more accurately. In contrast, coda often undergo various types of syllabic reduction where one or more phones of the coda are not pronunced at all (e.g., Greenberg et al., 2003).
Different languages employ different syllabic structures. Syllables (of a language) are sometimes denoted in terms of their constituent vowels (V) and consonants (C), where CV-syllables (one consonant onset + a vowel nucleus) are universally the most common. In addition, each language has its own inventory of syllables that can be of form CVC, CVV, CVCC, CVVCC etc.. For instance, English has on average quite long syllables, resulting on many monosyllabic words (bat: [b] [ae] [t], food: [f] [u:] [d], *laugh: *[l] [ae] [f]). In Finnish, CV syllables are frequent and hence many frequently spoken words emerge from combinations of several syllables (e.g., kissa : [k i s] . [s a] for *cat, *or nauraa: [n a u].[r a:] for to laugh; note that . marks for syllable boundary and : for a long vowel/consonant quantity).
2.3.2.3. Words#
Words are the minimum meaning-bearing units of spoken (and written) language, i.e., a word in isolation has some meaning attached to it. In contrast, isolated phones and syllables do not carry a meaning (unless the word is a monosyllabic one). Every word has at least one syllable, and, in principle, syllables do not cross word bondaries but align with them. In several languages, spoken words align relatively well with written words. However, words in speech are not separated by clear articulatory or acoustic markers, such as pauses, whereas written text transparently delimits individual words by intervening whitespaces.
2.3.2.4. Utterances#
Utterance is the smallest unpaused act of speech produced by one speaker, as delineated by clear pauses (or changes of speaker). In contrast to written language, where a sentence is one grammatical expression with a communicated meaning, utterances in spoken language can vary from individual words to much longer streams of words and grammatical constructs. In other words, speech does not consist of clearly delineated sentences (or clauses), but of speaking acts of varying durations. Speakers may use fillers (aka. hesitations, filled pauses) such as “uhm” or “ah” or prolonged vowels to signal that they aim to continue their utterance, but need some to reorganize their thinking in order to mentally construct the subsequent speech.
2.3.2.5. Morphological units#
Besides the above-listed units of speech, there are a number other units and structural concepts of language that linguistic theories make use of. They are perhaps less frequently utilized in speech processing, but become relevant when speech is being mapped to written language or vice versa, or when speech processing tools are used for linguistic research. One such an area of linguistics is morphology, which studies word forms, formation, and relationships between words in the same language. In morphology, morpheme is the smallest grammatical unit of speech, which may, but does not have to be, a word. Morphemes can be divided into free morphemes, which can act as words in isolation (e.g., “cat”), and bound morphemes, which occur as prefixes or suffixes of words (e.g., -s in “cats”). In addition, bound morphemes can be classified into inflectional morphemes and derivational morphemes. Inflectional morphemes change the grammatical meaning of the sentence, but do not alter the basic meaning of the word that is being inflected. Derivational morphemes alter the original word by creating a new word with a separate meaning. Allomorphs are different pronunciation forms of the same underlying morpheme.
Besides morphemes, morphology deals with lexemes. Lexeme is a unit of meaning from which different inflections (word-forms) can be derived. Hence, all words belong to some lexeme, but one lexeme can have many word-forms (e.g., “do”, “did”, “does”). Set of lexemes in a language is called a lexicon.
2.3.3. Prosody, aka. suprasegmental properties of speech#
Prosody aka. suprasegmental phenomena in speech refers to those patterns in speech that take place at time-scales larger than individual phones (segments). Many of the suprasegmental phenomena, such as intonation, stress, and rhythm, play a linguistic function, hence providing an additional means to alter the meaning and implications of spoken message without changing the lexical and grammatical structure of the sentence. Others are related to other information encoded in speech, such as cues for speaker’s emotional state, attitude, or social background. Here we only focus on those aspects of suprasegmentals that play a linguistic role.
2.3.3.1. Intonation#
Intonation corresponds to variations in fundamental frequency (F0) of speech as a function of time in speech, as perceived in terms of pitch. By altering the relative pitch as a function of underlying linguistic constituents or as a function of relative position in the utterance, the speaker can signal information such as emphasis, surprisal, question (vs. statement), or irony. For instance, English speakers often use falling intonation contour (across the utterance) for statements and rising intonation pattern for questions. Marking of focus and stress can be done with sudden increase in pitch during the marked syllable or word. In addition, tone languages (e.g., Mandarin Chinese) use pitch to phonemically to distinguish meanings of phonetically otherwise equivalent words. In general, the presence and function of intonational patterns depends on the language in question. Intonation can also contain other structural cues to speech, such as boundary tones to signify end of an sentence or utterance (Pierrehumbert, 1980), thereby also signifying end of an intonational phrase.
2.3.3.2. Stress#
Stress (aka. accent) corresponds to relative emphasis given to one syllable or word over the others in the given phrasal context. Stress can be realized by many means, including alternations in energy (loudness), pitch, and segment (typically vowel) duration with respect to the surrounding speech. Besides signifying emphasis, some languages also employ fixed or semi-regular stress patterns on words.
Word stress refers to the emphasis of a syllable or particular set of syllables within a word, and where multiple stressed syllables can be divided into those with primary and secondary stress. For instance, Finnish as nearly always primary stress on the first syllable of the word, and secondary stress falls on the following odd-numbered syllables. In English, words tend to have stress on the initial syllables, but there are multiple exceptions to this (e.g., word “guitar”, where the stress is on “-tar”). Some languages are sometimes considered to be completely void of stress.
Sentence stress (aka. prosodic stress) refers to stress on certain words or parts of words within an utterance, either signifying emphasis or contrast (e.g., “No, I went home” vs. “No, I went home”; stressed word highlighted).
2.3.3.3. Rhythm#
Speech rhythm is a result of complex interplay of several factors in speech production, where the flow of chosen words is also affected by stress patterns, segmental and pause durations, and general syllable structure of the given language. At a general level, rhythm refers to some kind of sense of recurrence in the speech, such as alternation between stressed and unstressed syllables.
A more narrow definition of rhythm relates to the idea of isochrony, according to which languages can be categorized into three rhythmic categories in terms of what is the determining recurrent structure in the signal (Pike, 1945; see also, e.g., Nespor et al., 2011). The first category consists of syllable-timed languages, where duration of each syllable is equal. The second corresponds to mora-timed languages, where duration of each mora is equal (see mora on Wikipedia). The last category consists of stress-timed languages, where the interval between stressed syllablees is equal. In practice, evidence for such a precise rhythmic regularities in actual speech data is limited, although many would likely agree that some languages tend to share some rhythmic characteristics that make them distinct from the rhythm of others.
2.3.4. Phonetic transcription and speech annotation#
Phonetic transcription is the process of marking down the phonetic structure of speech, typically aligned with the timeline of the speech waveform. Transcription is usually conducted according to IPA standards. The process can be carried out using either narrow transcription or broad transcription. In broad transcription, the marking typically consists of the most distinct phonetic elements in the speech data, such as individual phones and their basic allophonic variations. In phonemic transcription, which is the broadest level possible, only the phonemes corresponding to the speech are transcribed. In contrast, narrow transcription contains more phonetic detail regarding realization of the speech sounds. These details can include information on stress and intonation, and the transcription may also consists of diacritics, which provide more details on the articulatory/acoustic realization of the phones compared to their standard definitions in the IPA system (see the full IPA chart).
{kind=link}
Annotation of speech is a more general term than phonetic transcription. Annotations may consist of different layers of information in addition to (or instead of) the phonetic information. For instance, speech annotations may contain syllable and word boundaries and identities of the corresponding units. These identities can be marked down phonetically or ortographically, and are recorded either as actually pronunced or as canonical (i.e., as they would be listed in a dictionary). When contents of speech are marked as regular text, it is called orthographic transcription. Other commonly utilized annotation layers include utterance boundaries, speaker identities/turns, grammatical information such as parts of speech, morphological information, or potential presence of special non-speech events such as different categories of background noise. Since production of high-quality annotations usually requires manual human work and is very slow, different speech datasets tend to contain annotations that were of primary research interest to the person or team collecting and preparing the dataset.
Automatic speech processing tools can be of use in speeding up the annotation by, e.g., providing an initial version of annotations for humans to verify and correct. A particularly useful instance of automatic tools is the so-called forced-alignment with an automatic speech recognizer, which is suitable for cases where the acoustic speech signal and the corresponding spoken text are known. Assuming that the text is faithful to the underlying speech contents, a good recognizer can produce much more accurate phonemic transcription and/or timestamps for word boundaries than what would be achievable by regular automatic speech recognition without the reference text.
2.3.5. References#
S. Greenberg, H. Carvey, L. Hitchcock, and S. Chang. Temporal properties of spontaneous speech – a syllable centric perspective. Speech Communication, 31:465–485, 2003. URL: https://doi.org/10.1016/j.wocn.2003.09.005.
P. Hallé and A. Christia. Global and detailed speech representations in early language acquisition. In M. Weirich Fuchs, D. Pape, and P. Perrier, editors, Speech planning and dynamics. Peter Lang, Frankfurt am Main, 2012.
I. Y. Liberman, D. Shankweiler, W. F. Fischer, and B. Carter. Explicit syllable and phoneme segmentation in the young child. Journal of Experimental Child Psychology, 18:201–212, 1974.
J. Morais, A. Content, L. Cary, J. Mehler, and J. Segui. Syllabic segmentation and literacy. Language and Cognitive Processes, 4(1):56–67, 1989.
M. Nespor, M. Shukla, and J. Mehler. Stress‐timed vs. syllable‐timed languages. In van Oostendorp et al, editor, The Blackwell Companion to Phonology, pages 1147–1159. Blackwell, Malden, MA, 2011.
H. C. Nusbaum and J. DeGroot. The role of syllables in speech perception. In M. S. Ziolkowski, M. Noske, and K. Deaton, editors, Papers from the parasession on the syllable in phonetics and phonology. Chicago Linguistic Society, Chicago, 1991.
Janet B. Pierrehumbert. The Phonology and Phonetics of English Intonation. PhD thesis, Massachusetts Institute of Technology, 1980.
Kenneth L Pike. The Intonation of American English. University of Michigan Press, Ann Arbor, Mich., 1945.
J. F. Werker and R. C. Tees. Cross-language speech perception: evidence for perceptual reorganization during the first year of life. Infant Behavior & Development, 7(1):49–63, 1984. URL: https://doi.org/10.1016/S0163-6383(84)80022-3.
Also, substantial reuse of materials from related Wikipedia articles.